 Photo by rawpixel on Unsplash
Photo by rawpixel on Unsplash卷积神经网络CNN
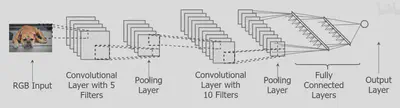
CNN 就是Convolutional Layer and Pooling Layer ,然后Convolutional Layer and Pooling Layer,然后再重复很多次,最后将池化层(Pooling Layer)展开成向量,即Fully Connected Layer,进行回归或分类(例如softmax进行分类)。
RGB Image(狗狗图片)有个小方块,conv layer with 5 filters就是有5个kernel(卷积核)的卷积层。
卷积神经网络(Convolutional Neural Network, CNN)中的激活函数位于卷积层之后,紧跟着卷积操作和(可选的)偏置项的加法。在经典的神经网络结构中,每个神经元的输出不仅仅是输入信号与权重的线性组合,还需要通过一个非线性函数(即激活函数)来引入非线性特性,以增强网络的学习能力和表达能力。这样做的原因是,很多真实世界的数据和问题本质上是非线性的,简单的线性模型难以有效捕获这些复杂关系。
卷积操作
 给个3x3 kernel,stride经过整个大的狗狗图像image,运算得到小的output(feature map)。所以,一个kernel 卷积操作得到一个feature map。
给个3x3 kernel,stride经过整个大的狗狗图像image,运算得到小的output(feature map)。所以,一个kernel 卷积操作得到一个feature map。

其它概念
padding 主要用于维持卷积操作后图像尺寸的一致性,或者为了满足特定神经网络层的输入尺寸要求。例如,在卷积神经网络(CNN)中,padding 可以在图像边缘添加一层或多层像素,以保持输出特征图与输入图像大小相同,或控制特征图的缩小程度。常用的 padding 类型有零填充(zero padding)、反射填充(reflect padding)和重复填充(replicate padding)。
膨胀卷积(Dilated Convolution)
膨胀卷积通过在标准卷积核的元素间插入空洞(或称为“洞”)来增加感受野(receptive field)的大小,而不需要增加卷积核的实际尺寸或减少输出特征图的空间分辨率。这意味着卷积核在输入数据上的滑动间隔增大,能够捕捉到更宽广的上下文信息,同时保持较低的计算复杂度。膨胀卷积通常由三个关键参数定义:卷积核大小(kernel size)、步长(stride)和膨胀率(dilation rate)。膨胀率决定了卷积核内部元素之间的空间跨度,比如膨胀率为2意味着核元素之间的间隔为1个空单元。其主要优势在于保持较高的空间分辨率,这对于语义分割、图像分类、场景解析等任务尤为重要,因为在这些任务中,保持精确的空间信息对于准确的像素级预测至关重要。通过膨胀卷积,模型可以在不牺牲分辨率的情况下,扩大感受野,捕获更多全局上下文信息。与标准卷积相比,膨胀卷积在相同的感受野下,可以减少卷积层的数量,有助于减轻模型的复杂性和计算负担。同时,它避免了池化操作可能带来的信息丢失问题,保持了更多的空间细节。
ResNet

网络亮点:1.超深的网络结构,2.residual模块,3.Batch Normalization加速训练(丢弃dropout)
残差结构
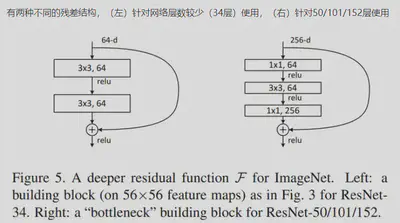
(左)参数个数:3×3×64×64 + 3×3×64×64
(右)参数个数:1×1×256×64 + 3×3×64×64 + 1×1×64(输入卷积核的通道数)×256(卷积核个数)
(1×1的卷积核用来降维和升维,可以大大减少参数量)
ResNet模型结构
根据layer的不同,ResNet模型分为5个版本:18/34(浅层);50/101/152(深层)
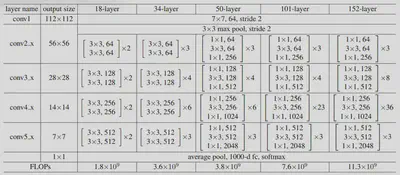
- conv2_x第一层为实线残差结构,因为通过最大池化下采样后得到的输出是[56,56,64],刚好是实线残差结构所需要的输入shape
- conv3_x第一层为虚线残差结构,输入特征矩阵shape是[56,56,64],输出特征矩阵shape是[28,28,128]
无论是浅层网络还是深层网络,conv3_x、conv4_x、conv5_x的第一层都为虚线残差结构,因为需要将上一层输出特征矩阵的高、宽、深度调整为当前层所需输入特征矩阵的高、宽、深度(Down-sampling is performed by conv3_1、conv4_1 and conv5_1 with a stride of 2)
Batch Normalization
在图像预处理过程中,通常会对图像进行标准化处理,由此加速网络的收敛,Batch Normalization的目的是使一批(batch)数据所对应feature map的每一个channel的维度满足均值为0、方差为1的分布规律。通过该方法能够加速网络的收敛并提升准确率。
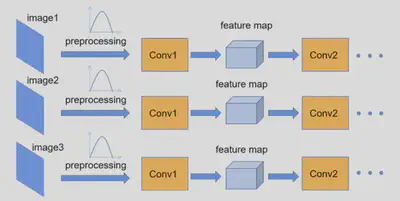
(将图像数据调整到满足某一数据分布规律(预处理,加速网络训练)再输入网络;但图像经过Conv1后得到的feature map不一定满足所期望的分布规律)
理论上是指整个训练样本集所对应feature map的数据要满足分布规律(即计算出整个训练集的feature map,再进行标准化处理),但这对于一个大型数据集来说明显是不可能的,故是一个batch数据的feature map
YvYve 陽
Freshman of Artificial Intelligence
I am now a newcomer to AI, so please take care of me and look forward to my growth!

